
How we built JSR

We recently launched the JavaScript Registry - JSR. It’s a new registry for JavaScript and TypeScript designed to offer a significantly better experience than npm for both package authors and users:
- It natively supports publishing TypeScript source code, which is used to auto-generate documentation for your package
- It’s secure-by-default, supporting token-less publishing from GitHub Actions and package provenance using Sigstore
- It rates packages using our “JSR Score” to give consumers an “at a glance” indication of the quality of a package
We knew that JSR would only gain adoption if it interoperates with the existing npm ecosystem. Below is the set of “npm interoperability” requirements we needed to meet with JSR:
- JSR packages can be seamlessly consumed by any tool that uses
node_modules/folders - You can incrementally adopt JSR packages in your Node projects
- npm packages can be imported from JSR packages, and JSR packages can be imported from npm packages
- Most existing npm packages written with ESM or TypeScript can be published to
JSR with very little effort - just run
npx jsr publish - You can use your favorite npm compatible package manager like
yarn, orpnpmwith JSR
Our open beta launch of JSR was met with enthusiasm from the community, as we’ve
already seen some great packages being published already, such as the typesafe
validation & parsing library @badrap/valita
and the multi-runtime HTTP framework @oak/oak.
But this blog post is not about why you should use JSR. It’s about how I and the rest of the JSR team, over the course of several months, built JSR so meet the technical requirements of a modern, performant, highly available JavaScript registry. This post covers nearly every part of JSR:
- Overview of technical specs
- Minimizing latency for the jsr.io website
- Building a modern publishing flow (aka say no to probing!)
- Serving modules at 100% reliability
- So that’s it?
I will try to explain not just how we do something, but also why we do things in the way we do. Let’s dive in.
Overview of technical specs
For JSR to be a successful modern JavaScript registry, it must be many things:
- A global CDN to serve package source code and NPM tarballs
- A website that users use to browse packages and manage their presence on JSR
- An API that the CLI tool talks to publish packages
- A system to analyze source code during publishing to check for syntax errors or invalid dependencies, to generate documentation, and to compute package scores
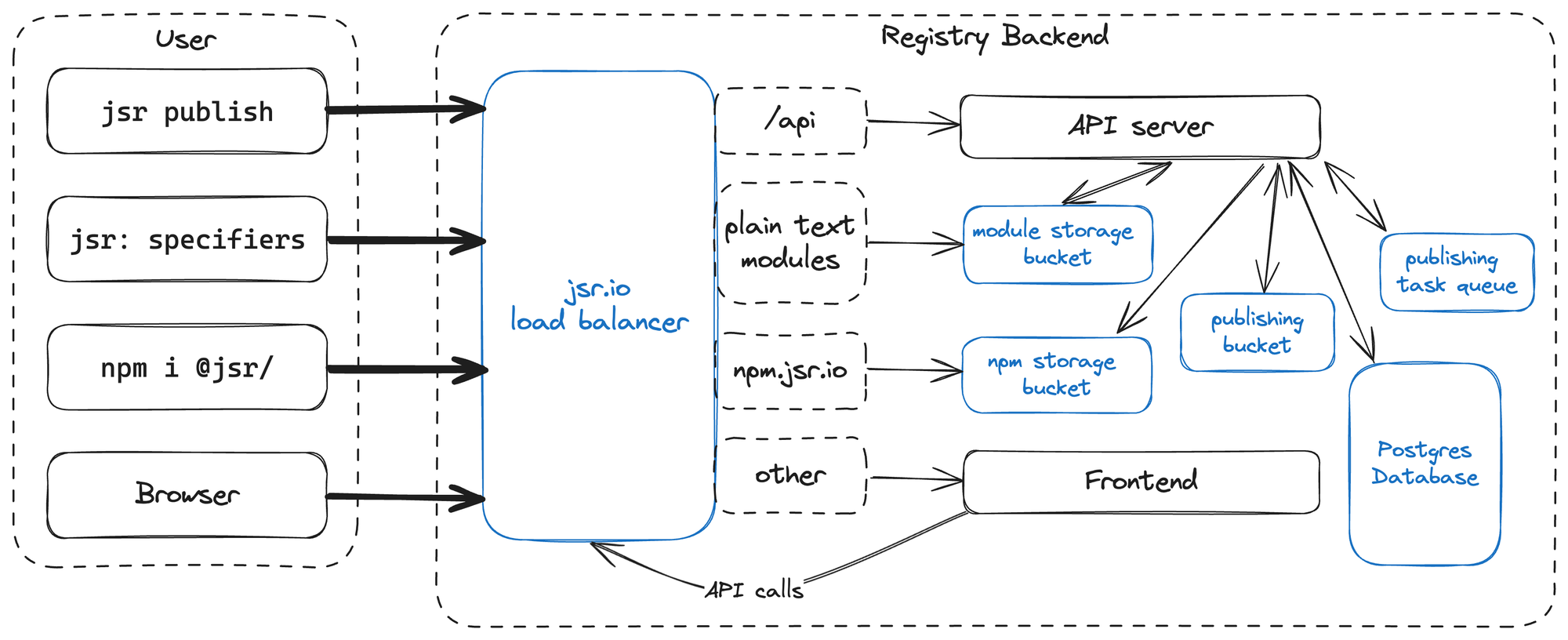
The challenge with building something that satisfies all those conditions is that they each have different constraints.
For example, the global CDN must have a near 100% uptime. It is unacceptable if downloading a package fails for even 0.1% of users. If a package download fails, that is a broken CI run, a confused developer, and a very bad user experience. Any decently sized project will struggle with flaky CI at some point already - I don’t want to add to that 😅.
On the other hand, if a user receives a scope invite email 10 minutes after they have been invited, that’s much less of an issue. It’s not a great user experience (we still try to avoid this), but it’s not a critical flaw that will require paging an on-call engineer in the middle of the night.
Since reliability is a core part of JSR, these tradeoffs determine how JSR and its various components are architected. Each part has varying service level objectives (SLOs — how reliability is usually defined): we target an SLO of 100% uptime for serving package source code and NPM packages, whereas other services (like our database) target a more conservative 99.9% uptime. Throughout this post, we’ll be using SLO as the starting point for determining how we approached designing a piece of the system.
Postgres for most data
JSR uses a highly-available Postgres cluster to store most data. We have tables
for obvious things like users, scopes, or packages. But we also have
larger tables, like our package_version_files table, which contains metadata
like path, hash, and size of all files ever uploaded to JSR. Because
Postgres is a relational database, we can combine these tables using JOINs to
retrieve all kinds of fun information:
- How much storage space does this user consume?
- How many files are duplicated across JSR packages?
- What packages were published within an hour of the creator signing up to JSR?
We use the excellent sqlx Rust package
to handle migrations. You can look at all of the migrations
that create the JSR database on GitHub.
Our Postgres database is hosted on Google Cloud (like the rest of JSR!). We’ve had great experiences with Google Cloud in the past, so we decided to use it again here. Google Cloud has very nice tooling and documentation for Terraform, which is the Infra-as-Code tool we use to deploy JSR (could do a whole blog post on this).
API
Right above the Postgres database sits our API server. JSR does not directly
expose the Postgres database to clients. Instead we expose the data in the
database via JSON over a HTTP REST API. API requests can come from multiple
different kinds of clients, including from users’ browsers, or from the
jsr publish / deno publish tool.
The JSR API server is written in Rust, using the
Hyper HTTP server. It communicates with the Postgres
database via the sqlx Rust crate. The
service is deployed to Google Cloud Run, in one region, right next to the
Postgres database.
In addition to proxying data between the database and the JSON API interface, the API server enforces authentication and authorization policies, like requiring that only scope members can update a packages’ description, or ensuring that only the right GitHub Actions job can be used to publish a package.
At the end of the day, the API server is a relatively standard service that could exist in a very similar form in any of 100’s of other web applications. It interacts with a SQL database, sends emails using an email service (in our case, Postmark), talks to the GitHub API to verify repository ownership, talks to Sigstore to verify publish attestations, and much more.
Minimizing latency for the jsr.io website
If you’re writing a service for humans to use, you discover pretty quickly that
most humans do not in fact want to manually invoke API calls using curl.
Because of this, JSR has a web frontend, which lets you perform every single
operation that the API exposes (except for publishing packages —
more on this later).
To keep the jsr.io website feeling fast and snappy, we built it with Fresh, a modern “server-side render first” web framework built here at Deno. That means every page on the JSR website is rendered on demand in a Deno process running in a Google Cloud data center near you, just for you. Let’s explore some approaches Fresh uses to ensure site visitors get the best experience.
Island rendering for performance
Fresh is quite unique in that unlike other web frameworks like Next.js or Remix, it does not render the entire application both on client and server. Instead, every page is always rendered entirely on the server and only sections marked interactive are rendered on the client. This is called “island rendering”, because we have little islands of interactivity in a sea of otherwise server rendered content.
This is a very powerful model that allows us to provide both incredibly snappy page rendering for all users, regardless of their geolocation, internet speed, device performance, and memory availability, and really nice interactive user flows. For example, because of our island architecture the JSR site can still support “search as you type”, and client-side validation for scope names before form submission, even while using serve side rendering. All without having to ship a markdown renderer, styling library, or a component framework to the client.
This really pays off:
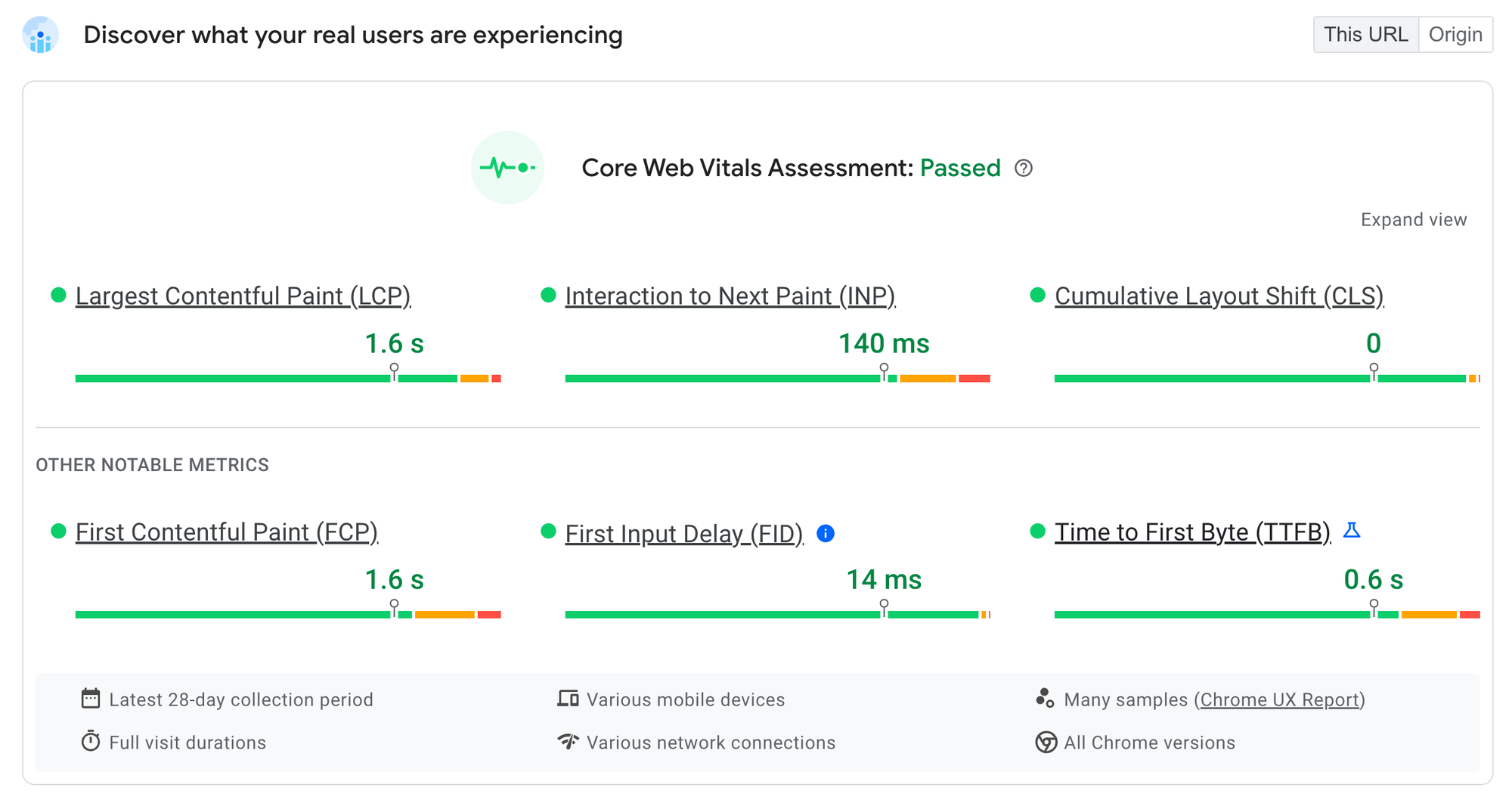
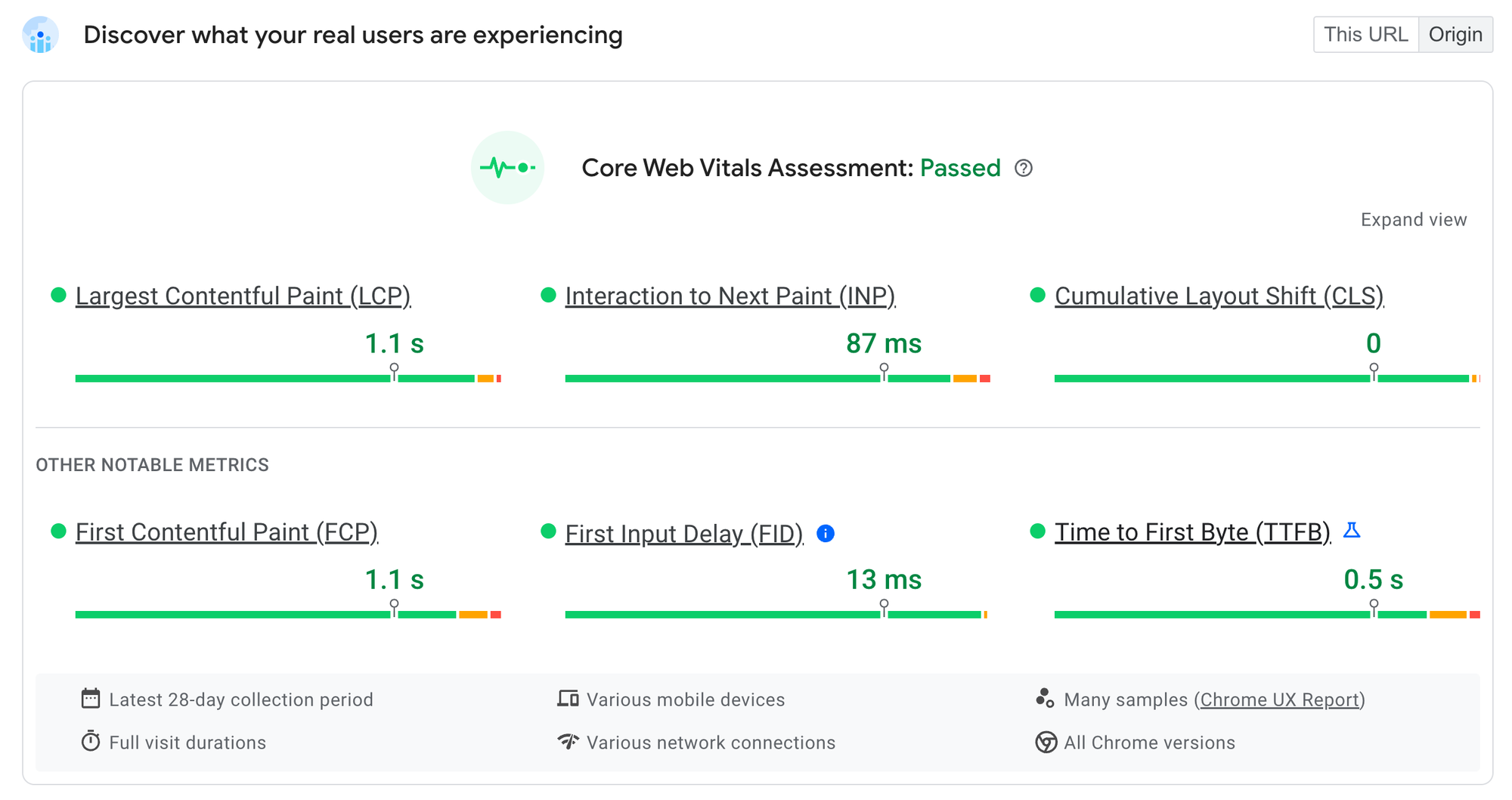
Real user data from the Chrome UX report (anonymous statistics on performance collected by Chrome in the background), show that https://jsr.io has great performance on a variety of devices, on a variety of networks. Particularly exciting is the excellent score for the new Interaction to Next Paint (INP) metric, which measures how contended the main thread is with rendering and represents how fast interactions “feel”. Because of Fresh’s island architecture, JSR scores incredibly well on metrics like these.
Optimizing for time-to-first-byte
Another thing you may notice here is the TTFB performance. The TTFB metric represents the 75th percentile of “time-to-first-byte” - the time between hitting enter in your URL bar and the browser receiving back the start of the response from the server. Our TTFB score of 0.5s is great, especially for a dynamically server side rendered site. (Server rendered sites tend to have a higher TTFB, because they wait for dynamic data on the server, rather than serving a static shell on the client and then fetching dynamic data from the client.)
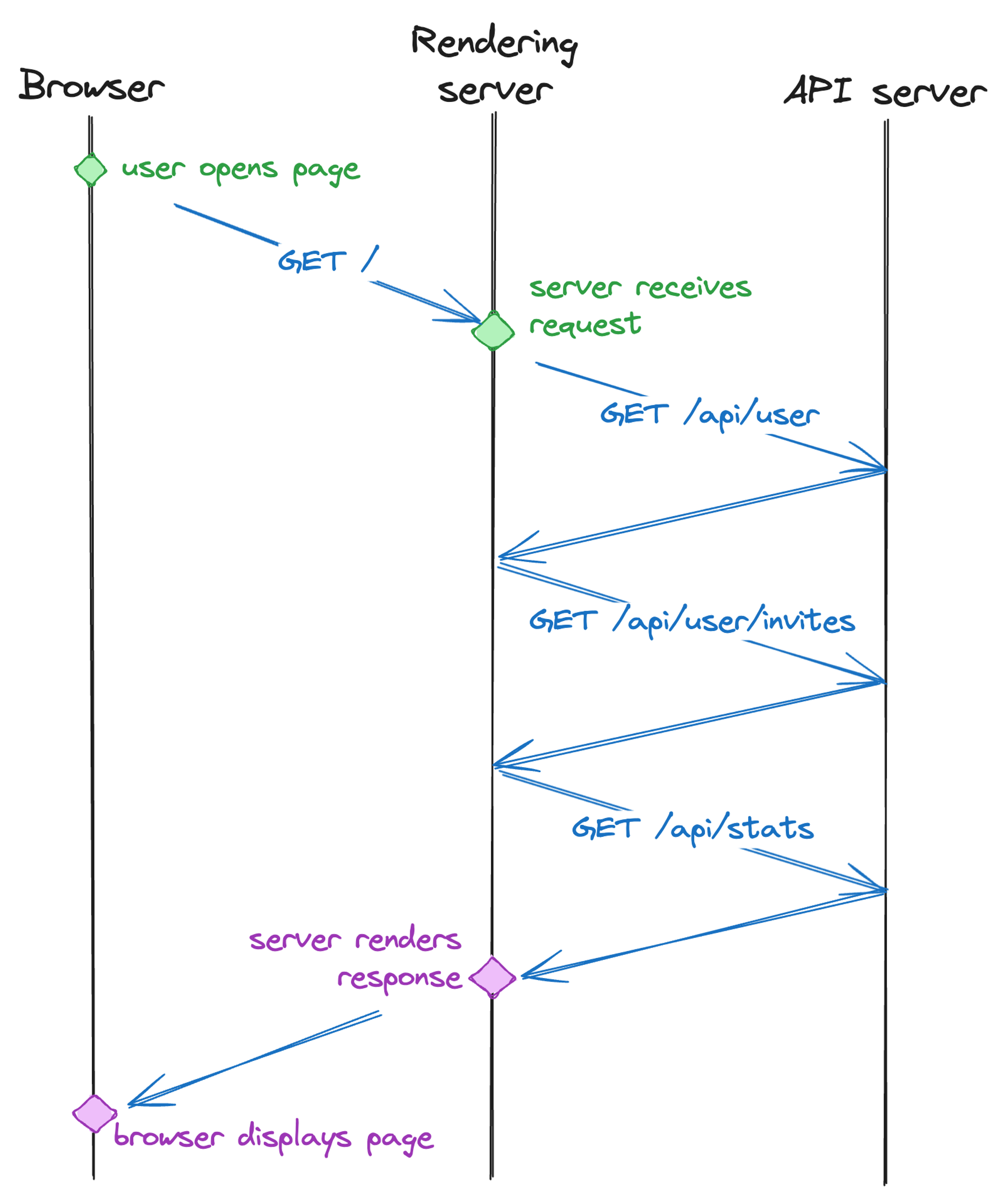
We spent a lot of time optimizing for TTFB, which can be a real challenge for server side rendered pages. Because the entire page rendering is blocked until all data is present on the server, the time it takes the server to retrieve all of the data it needs needs to be reduced as much as possible. In the first few weeks of our work on JSR, I would frequently get reports from colleagues in India and Japan that the JSR package page was unbearably slow to load - multiple seconds for a simple package settings page.
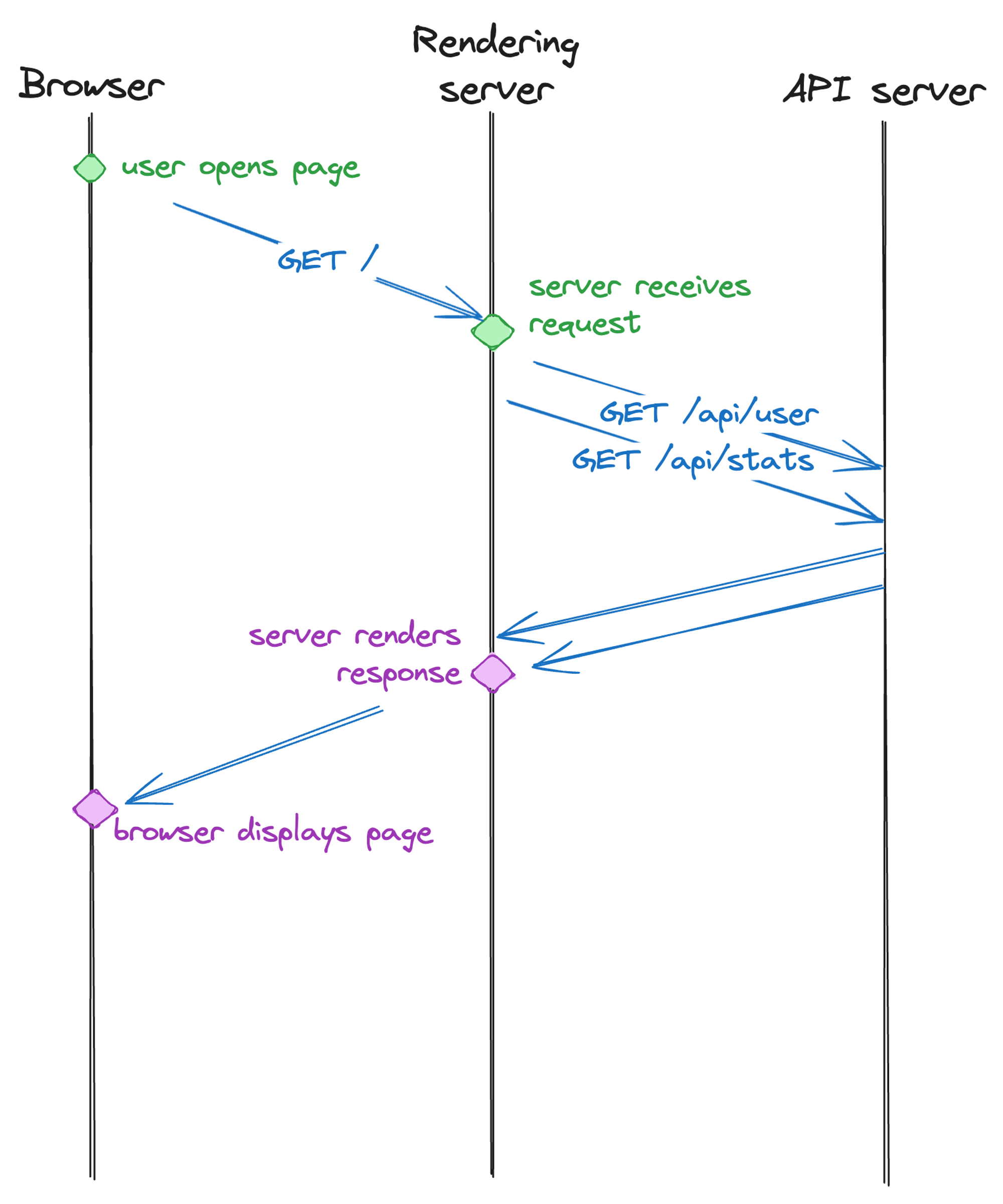
We managed to narrow this down to a waterfall of requests between the server rendering the page, and our API server. We’d first fetch the user profile, then fetch the package metadata, then fetch whether the user is a member of the scope, and so on. Because our API server is hosted in the US (pretty far away from India), and even the internet needs to adhere to the physical constraints like the speed of light, it would take seconds for us to have all the data needed to render.
We are now at a point where there is not a single route on the JSR site that requires more than one network roundtrip between rendering server and API server. We managed to parallelize many of the API calls, and in other cases improve the API in subtle ways to not require multiple requests at all anymore. For example, initially the package page would first fetch the package version list, figure out what version is the latest one, then fetch the readme for that version. Now, you can just tell the API endpoint that returns the readme that you would like the readme for the “latest” version and it can figure out what that is quickly from it’s co-located database.
Using <form> wherever possible
It might seem weird to rely on built-in browser <form> submissions wherever
possible. (We use <form>’s even in unusual places, like the “Remove” button
next to users in a scopes’ scope member list.) However, doing this allows us to
significantly reduce the amount of code we have to write, ship to users, and
audit for accessibility.
Accessibility is an important aspect of web development, and using more built-in browser primitives significantly decreases the amount of work you have to do yourself to get a good outcome.
Have I mentioned yet that all of this is open source? The JSR frontend is probably the easiest piece to contribute to:
git clone https://github.com/jsr-io/jsr.git
cd jsr
echo "\n127.0.0.1 jsr.test" >> /etc/hosts
deno task prod:frontendThis will spin up a local copy of the frontend for you to play with, connected
to the production API. If you make a change in the frontend/ folder, your
local frontend at http://jsr.test will automatically reload. You can even manage
your scopes and packages from the production JSR service using your local copy
of the site!
Building a modern publishing flow (aka say no to probing!)
We’ve talked a lot about managing metadata on packages (the API server), and viewing this metadata (the frontend), but really - what is a package registry if you can’t publish to it?
Building a modern JavaScript registry that must interoperate with npm means being able to accept a wide, diverse set of packages. Module authors should be able to publish:
- existing NPM packages authored in TypeScript with a
package.json - packages authored for Deno using an
import_map.json - even a single JS file that re-exports a package imported from npm
The challenge of building a registry that supports accepting a diverse set of packages means we must understand and support all kinds of module resolution methods:
- Files are imported with the actual extension they use (
.tsfor importing TS files) - Files are imported with no extension at all
- Files are imported with the wrong extension (
.jsimports actually refer to TS files with a.tsextension) - Bare specifiers resolved in import maps
- Bare specifiers resolved via package.json
- … and more
Despite these complexities of supporting publishing a diverse set of packages, we knew early on that JSR package consumers should not need to know these intricate differences. We’re trying to push the ecosystem into a consistent, vastly simpler direction: ESM-only and very explicit resolution behaviour. In order to deliver a world class developer experience for package consumers, JSR must ensure a consistent format of code to download.
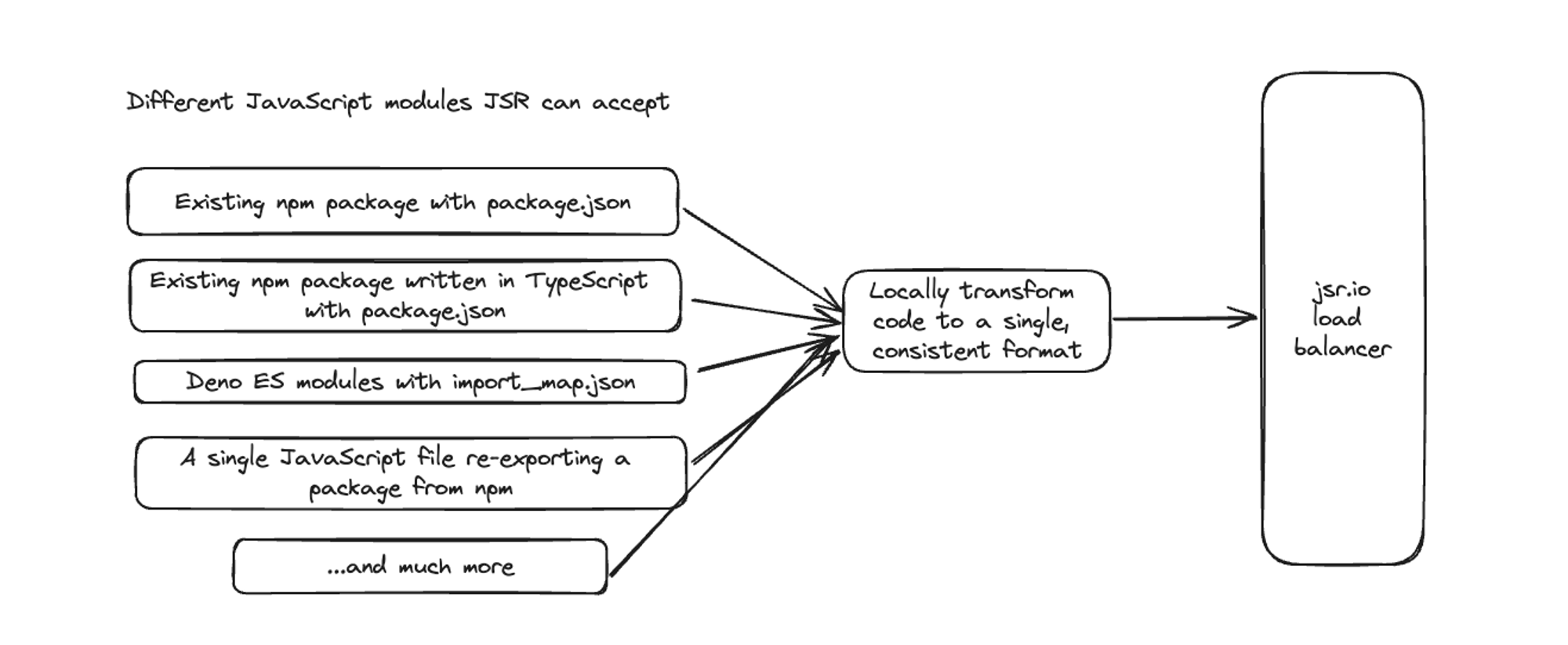
So how can we support accepting a diverse set of packages, while still providing a simple standard package consumption experience?
When an author publishes to JSR, we automatically “fix it” by converting it into a consistent format for the registry. As the package author, you don’t have to know, care, or understand that it’s happening. But this code transformation speeds up and simplifies the registry.
Then, the question is what is this “consistent standard” format?
Say no to probing
Before we go any further, first a little aside on “probing”. (Oh … I shiver just saying it.) Probing is the practice of giving unclear instructions to someone who then tries many things until something works. Confused? Here’s an example.
Imagine you work at the supermarket and stocked the fruits today. After coming home, you decide you want some pineapple. You send someone to the supermarket to pick some up, but instead of telling them to get a pineapple, you say “get me any fruit that is in stock, that starts with a letter ‘p’, here is my priority order: papaya, pear, pineapple, passionfruit, peach”.
Your runner goes to the fruit section in the supermarket and starts looking. No papayas today. Pears? Nope. But lo and behold — pineapples! They grab some and return to you, victorious.
But that was the neighbourhood grocer, where you can see the entire fruit display at a glance, so checking for fruit is quick. What if we were at a wholesale fruit market? Each continent’s fruits are now in their own section in a giant warehouse. Walking between the papaya’s, the pears, and the pineapples takes minutes. “Probing” for fruit really falls apart here since it takes so long that it becomes infeasible.
So how does this clumsy approach to buying fruit tie back to a consistent
standard code format? Well, a lot of the resolution algorithms probe:
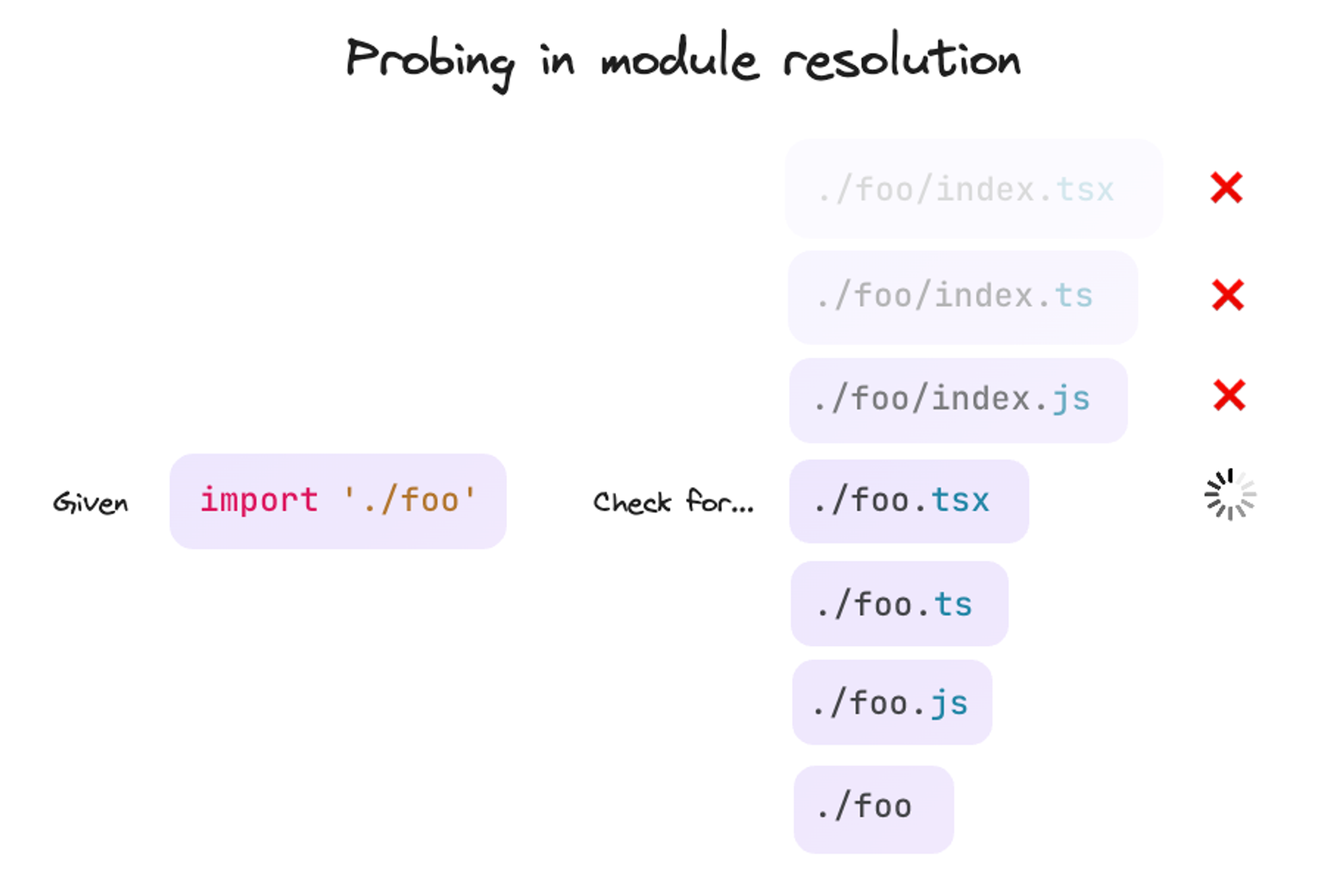
import './foo' needs to check if there is a file called ./foo/index.tsx,
./foo/index.ts, ./foo/index.js, ./foo.tsx, ./foo.ts, ./foo.js, or even
just ./foo. As the package author, you know which file you want to resolve to.
But you’re sending the resolver on a fun adventure of “try to open a bunch of
files and see if they exist”. Whoops.
When you do this on a local file system, the performance is often acceptable. Reading a file takes a couple hundred nanoseconds on a modern SSD. But “probe” on a network drive - already much slower. And over HTTP - you’re waiting 10s of milliseconds for every read call. Completely unacceptable for 100’s of files in a package.
Because JSR packages can not just be imported from the file system, but also
using HTTP imports (like browsers and Deno), probing is a total no go.
(Coincidentally you now also know why browsers could never ship node_modules/
resolution like Node: too much probing.)
Locally rewrite import statements to remove probing during publish
With probing being out of the question, our consistent standard format for end users and JSR to consume must follow this one main rule:
Given ONLY the specifier and contents of a module, you can accurately determine the exact names of all files imported from within that package, and the name and version constraints of all external packages.
Practically speaking, this means we cannot rely on package.json to resolve
dependencies and that all relative imports must have explicit extensions and
paths. So to support accepting a broad and diverse set of packages, we first
must re-write the code before it even hits the JSR API layer.
When you call jsr publish or deno publish, the publishing tool will inspect
your code, probe for package.json, an import map, and whatever else you use to
configure your resolution, and then walk through all the files in your package,
starting at the "exports" in your jsr.json. It then finds any imports that
would require probing to resolve, and rewrites them to the consistent format
that does not require probing:
- import "./foo";
+ import "./foo.ts";- import "chalk";
+ import "npm:chalk@^5";- import "oak";
+ import "jsr:@oak/oak@^14";This all happens in memory, without the package author having to see or know that this is happening. This local code translation to a consistent format is the magic that enables a modern, flexible publishing experience where authors can write in whatever way they want and users can consume packages in a simple, standardized way.
Using background queues for availability
Next up, the publishing script places all the files into a .tar.gz file. After
getting the user to interactively authenticate the publish (this could be it’s
own whole blog post 👀), it uploads the tarball to the API server.
The API server then does some initial validations like checking that the tarball is smaller than the 20MB allowed and that you have access to publish this version. Then it stores the tarball in a storage bucket and adds the publishing task to a background queue.
Why add it to a queue rather than processing the tarball immediately? For reliability.
Part of reliability is handling spikes of traffic. Since publishing is an intensive process that requires a lot of CPU and memory resources, a large mono repo publishing new versions for 100 different packages all at once could slow the entire system to a crawl.
So we store the tarballs, put them in a queue, and then background workers pick up publishing tasks out of the queue and process them, as they have availability. 99% of publishes go from submission to dequeuing by a background worker in under 30 milliseconds. However if we do see large spikes, we can gracefully handle these by just slowing down the processing a bit.
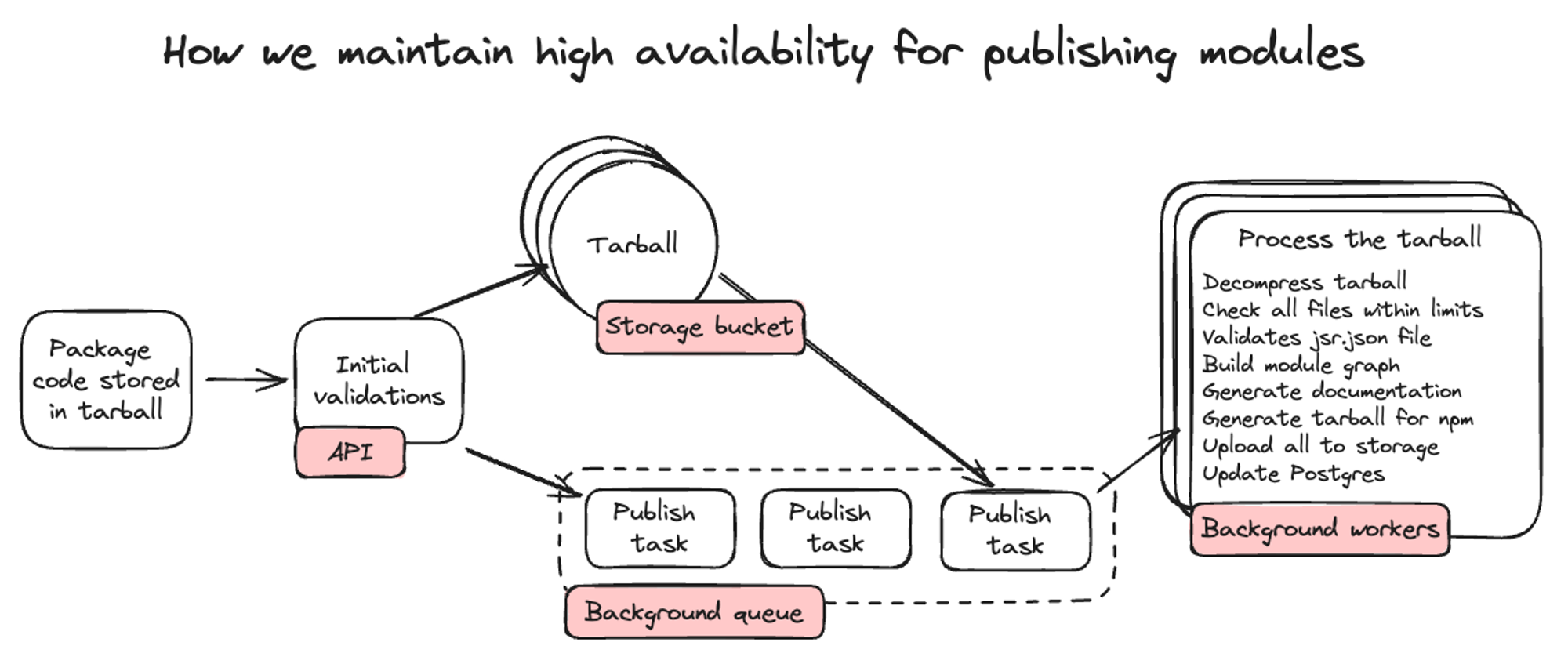
When a background worker picks up a publishing task, it starts by decompressing
the tarball and checking all files inside are within our acceptable limits. It
then validates that the jsr.json file has a valid "name", "version", and
"exports" field. After this, we build a module graph of the entire module,
which helps validating the package code. The module graph, which maps the
relationship between every module in a package, checks that:
- your code is valid JavaScript or TypeScript
- all your imported modules actually exist
- all your dependencies are versioned
This all happens within 10s of milliseconds for most packages.
Auto generating docs and uploading the module to storage
After validation is complete, we generate documentation for the package based on this module graph. This is done entirely using TypeScript syntax analysis in Rust. The result is uploaded to a storage bucket. We’ll write another blog post on how this works at some point, as it’s quite interesting!
Then, we upload each module individually (exactly as it is, no transforms occur
here) to a modules storage bucket. This bucket will be important later,
remember it!
Turning TypeScript into .js and .d.ts files for npm
Next up, we generate a tarball for JSR’s npm compatibility layer. To do this, we
transform your TypeScript source code into a .js code file, and .d.ts
declaration file. This is done entirely in Rust - to our knowledge, this is the
first large scale deployment of .d.ts generation that does not use Microsoft’s
TypeScript compiler written in JavaScript (exciting!). The code in this tarball
is rewritten from JSR’s consistent module format back into imports that
node_modules/ resolution understands, along with a package.json. Once done,
this is also uploaded to a bucket.
Finally, we’re done. The Postgres database is updated with the new version, the
jsr publish / deno publish command is notified that the publish is done, and
the package is live on the internet. When you go to https://jsr.io now, the
updated version will show up on the package page.
🚨️ Side note 🚨️
We’re super excited about our ability to generate
.d.tsfiles from.tssource, without usingtsc. This is something TypeScript is actively trying to encourage. For example, Bloomberg and Google, in collaboration with the TypeScript team, have been working on adding anisolatedDeclarationsoption to TypeScript that will make declaration emit outside of TSC a breeze. We’re bullish that soon, many more tools will have the ability to emit.d.tsfiles without usingtsc.
Serving modules at 100% reliability
I’ve beaten around the bush enough now - this blog post started with me telling you how it’s really important that our module / npm tarball serving is super robust. So what’s the magic sauce?
Actually, there is no magic. We use incredibly boring, very well understood, and very reliable cloud infrastructure.
https://jsr.io is hosted on Google Cloud. Traffic is accepted by a Google Cloud L7 load-balancer via anycast IP addresses. It terminates TLS. It then looks at the path, request method, and headers to determine whether the request should go to the API server, the frontend, or to a Google Cloud CDN backend that directly fronts a Cloud Storage bucket containing source code and npm tarballs.
So how do we make serving modules reliable? We defer the entire problem to Google Cloud. The same infrastructure that serves google.com and YouTube is used to host modules on JSR. None of our custom code sits in this hot path - which is important because that means we can not break it. Only if Google itself goes down, will JSR come down too. But at that point - probably half the internet is down so you don’t even notice 😅.
So that’s it?
For the registry side, yeah, mostly. I left out how we do the documentation rendering, how we compute the JSR score, compute package dependencies and dependents, handle the OIDC integration with GitHub Actions, integrate with Sigstore for provenance attestation… but we can talk about that next time 🙂.
If you are interested in anything I mentioned in this post — from
the API server,
to
the frontend
and
Terraform configuration for Google Cloud,
to the implementation of
deno publish
— you can take a look at them yourself, as JSR is completely open source under
the MIT license!
We welcome all contributors! You can open issues, submit PRs, or ask me things on Twitter.
See you on JSR!
Did you enjoy this post on JSR’s internals?
We have another post coming soon with all the nitty gritty of how
denoinstalls packages from JSR. Follow us on Twitter to get updated: @jsr_io or @deno_land.