
Announcing self-hosted Deno KV, continuous backups, and replicas



When we first announced Deno KV, developers were captivated by the promise of a zero-config, strongly consistent, and globally replicated database crafted for JavaScript. The concept of adding state to servers, functions, and applications using just a single line of code has been well-received.
const kv = await Deno.openKv();As we expanded Deno KV with features like TTL, remote connections to hosted databases, read replicas for reduced latency, and Deno Queues, the issue of potential vendor lock-in emerged. We understand the importance of this concern. Deno is intentionally built on web standards. This aligns with our philosophy: knowing Deno means knowing the web, which empowers you to reach over a billion internet users.
In line with our commitment to flexibility and openness, we’re excited to roll out these new features, empowering you to leverage Deno KV in the way that best suits your needs:
- Self-host Deno KV with
denokv - Continuous backup into S3 or GCS
- Self-host a Deno KV replica
- Point-in-time Recovery
- What’s next
This release marks a significant step towards offering a versatile and powerful database solution. It can be customized for any environment, from cloud-native applications to on-premises deployments.
Self-host Deno KV with denokv
Deno KV currently comes in two flavors:
- baked into the Deno runtime, backed by SQLite running in-process, useful for testing, development, and single-server production use-cases
- hosted on Deno Deploy, backed by FoundationDB, with seamless scaling and global replication, useful for production apps and enterprise use-cases
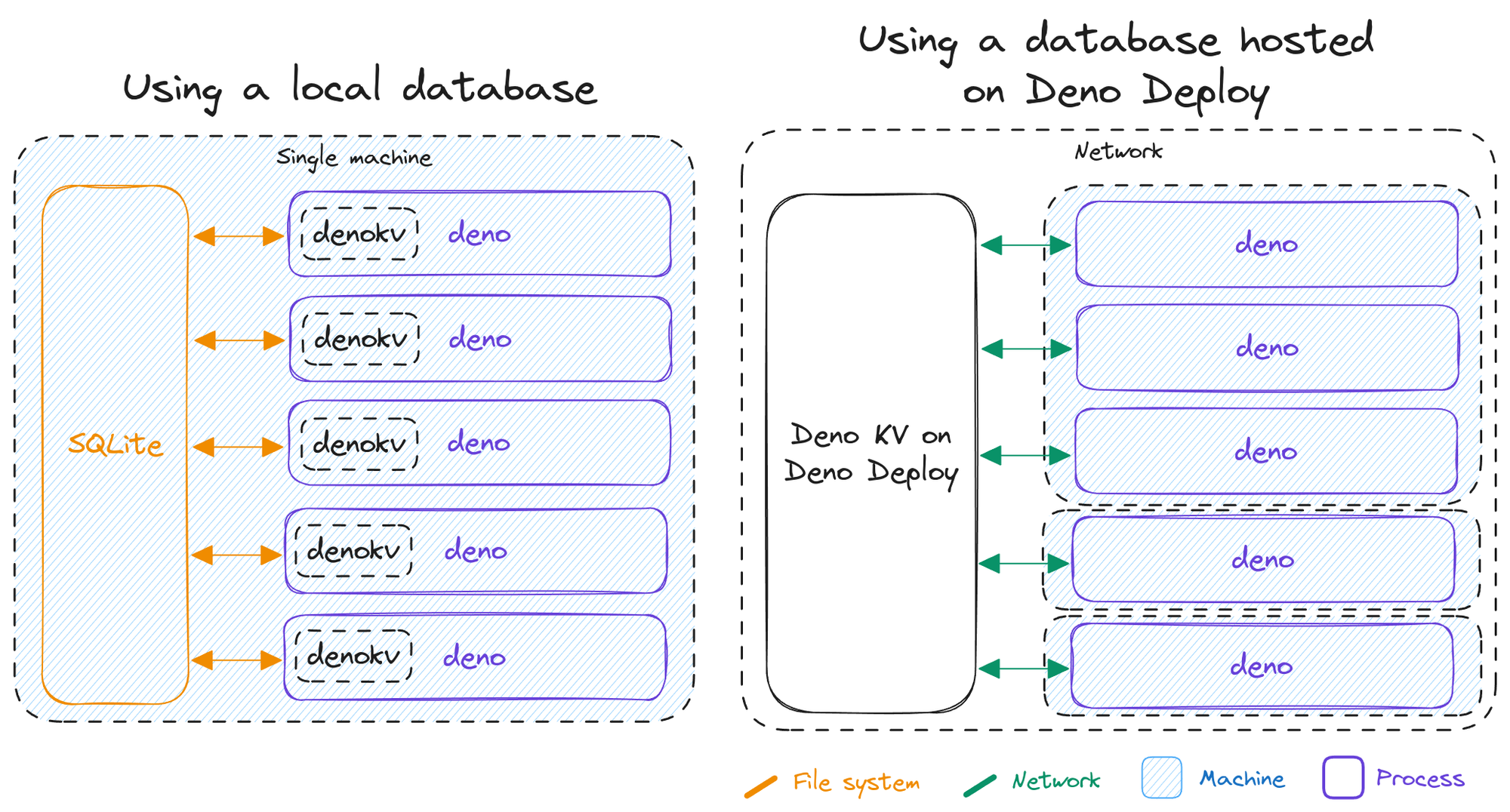
Today, we’re announcing a third way to use Deno KV for users who prefer to
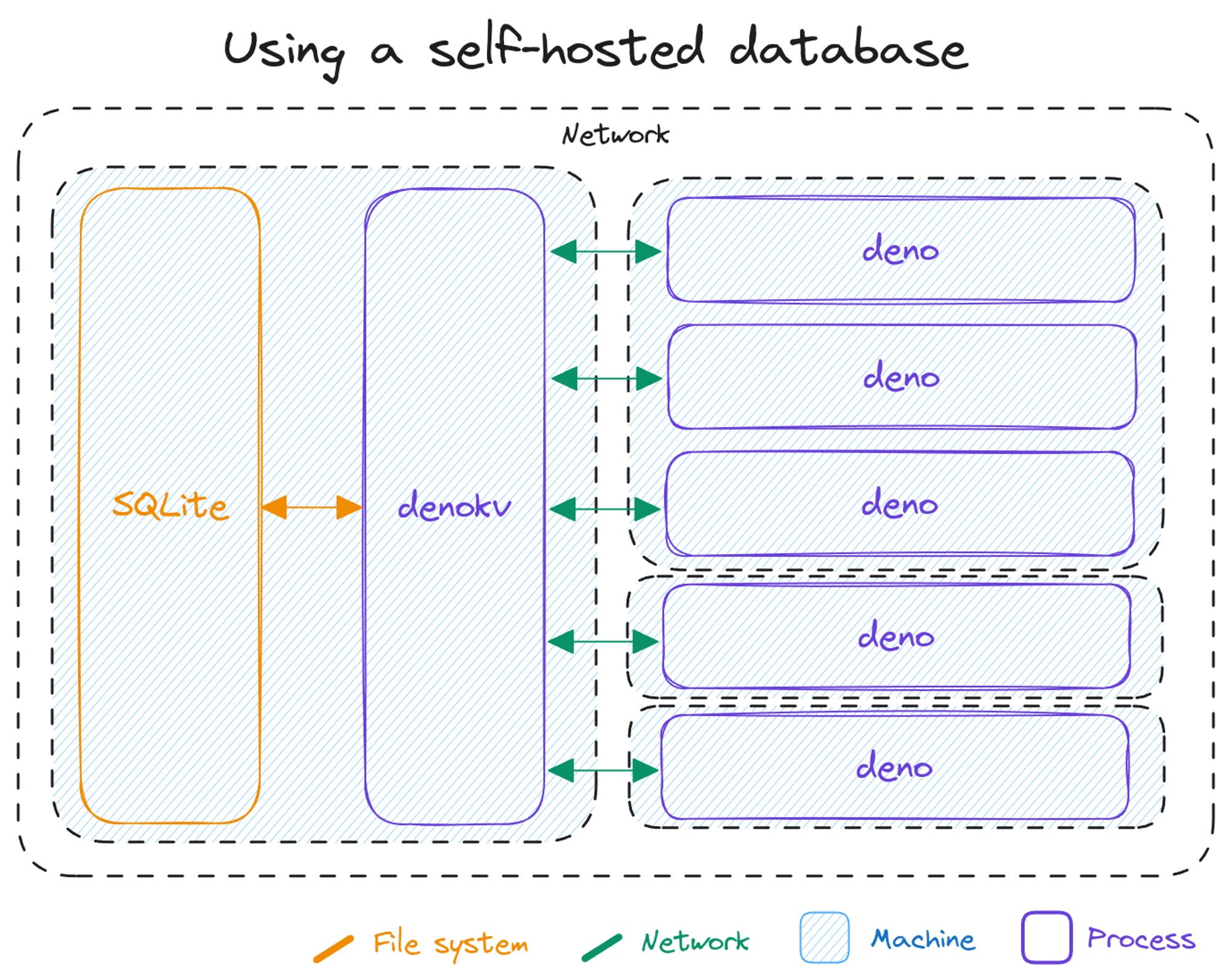
self-host their database: a standalone
denokv binary that you can run on your
own server and connect to from the Deno CLI via
KV Connect.
Just like Deno itself, this binary is
open source, MIT licensed, and perpetually
free to use.
The standalone denokv server is backed by the same robust SQLite backend that
powers the Deno KV implementation baked into the Deno CLI. This enables you to
integrate with the wide array of SQLite tooling for backups, replication,
point-in-time-recovery (PITR), and so on.
To start a standalone denokv server, simply execute a single docker command.
This mounts a local folder into the container to store the database, and it
hosts a KV Connect endpoint at http://localhost:4512 for connections.
$ export DENO_KV_ACCESS_TOKEN=$(openssl rand -base64 15)
$ docker run -it --init -p 4512:4512 -v ./data:/data ghcr.io/denoland/denokv --sqlite-path /data/denokv.sqlite serve --access-token $DENO_KV_ACCESS_TOKEN
Opened database at /data/denokv.sqlite
Listening on http://0.0.0.0:4512You can then just connect as usual with
Deno.openKv:
const kv = await Deno.openKv("http://localhost:4512");
await kv.set(["users", "alice"], {
name: "Alice",
birthday: new Date(2018, 5, 13),
});
const { value } = await kv.get(["users", "alice"]);
console.log(value);If you’re interested in trying it out, we’ve created
a guide for running the
standalone denokv server on Fly.io.
Be aware that unlike our hosted offering on Deno Deploy, you are fully responsible for backups, replication, scaling, and high availability when using the standalone
denokvbinary. We recommend you configure a tool like Litestream or LiteFS to continually backup the SQLite database thatdenokvuses.
Continuous backup into S3 or GCS
We’re excited to announce that starting today, you can continuously replicate or backup the data stored in Deno KV databases hosted on Deno Deploy to your own S3 or Google Cloud Storage buckets. This is in addition to the continuous backups that we internally perform for all data stored in hosted Deno KV databases to ensure high availability and data durability.
This replication happens continuously with very little lag, enabling point-in-time-recovery and live replication. Enabling this replication unlocks various interesting use-cases:
- Retrieving a consistent snapshot of your data at any point in time in the past
- Running a read-only data replica independent of Deno Deploy
- Pushing data into your favorite data pipeline by piping mutations into streaming platforms and analytical databases like Kafka, BigQuery and ClickHouse
You can set up replication on Deno Deploy in just a few steps. We have an in-depth guide walking you through the process for both S3, and Google Cloud Storage buckets in the documentation.
Once your replication target is in the “Active” status, the replication is up to date and a consistent copy of the Deno KV database are stored in the bucket. While in the “Active” status, new mutations are continually written to the bucket in real time to keep the replica up to date.
But now, how do you read the data back out of the bucket?
Self-host a Deno KV replica
This is where the third new feature for today comes in: self-hosting a replica
of your Deno KV database hosted on Deno Deploy. For this, we’ll use the denokv
tool from earlier again, with the --sync-from-s3 flag. This will create a
local replica of the data in the S3 bucket, continually syncing and keeping the
local replica up-to-date with the data in the bucket:
$ export AWS_REGION=us-east-1
$ export AWS_ACCESS_KEY_ID=your-access-key
$ export AWS_SECRET_ACCESS_KEY=your-secret-key
$ export DENO_KV_ACCESS_TOKEN=$(openssl rand -base64 15)
$ denokv --sqlite-path=./data.sqlite3 serve --sync-from-s3 --s3-bucket your-bucket --s3-prefix some-prefix/6aea9765-2b1e-41c7-8904-0bdcd70b21d3/
Initial snapshot is complete, starting sync.
Listening on http://localhost:4512Now you can connect to the local server with
Deno.openKv:
const kv = await Deno.openKv("http://localhost:4512");
const { value } = await kv.get(["users", "alice"]);
console.log(value);This is a read-only replica. Write operations like
kv.set()are not supported.
In addition to a consistent snapshot of the remote database, the local replica also contains the entire history of the database since the S3 backup target was added. This can be used for point-in-time recovery: the ability to view the data in your database like it was at any point in time in the past.
Point-in-time recovery
After the initial sync of the local database has completed, you can use the
subcommand denokv pitr list to list all recoverable points:
$ denokv --sqlite-path=./data.sqlite3 pitr list
0100000002d0fa520000 2023-11-09T10:37:23.935Z
0100000002d0fa510000 2023-11-09T10:37:23.935Z
0100000002d0fa500000 2023-11-09T10:37:23.935Z
0100000002c0f4c10000 2023-11-09T09:19:00.603Z
0100000002c0f4c00000 2023-11-09T09:19:00.603Z
0100000002b0ef310000 2023-11-09T09:15:32.815ZTo checkout a specific recoverable point, first stop any
denokv serve --sync-from-s3 processes currently running on this database.
Then, run denokv pitr checkout:
$ denokv --sqlite-path=./data.sqlite3 pitr checkout 0100000002b0ef310000
Snapshot is now at versionstamp 0100000002b0ef310000You can now restart denokv serve, this time with the --read-only flag
instead of the --sync-from-s3 flag. Now, all clients that connect to this
database will see the data as it was at timestamp 2023-11-09T09:15:32.815Z.
Note that the --sync-from-s3 flag of denokv serve automatically syncs and
keeps the latest snapshot checked out, so you should not explicitly specify this
if you have checked out a specific versionstamp.
What’s next
Deno KV, along with Deno Queues, web standards APIs, and npm are key building blocks that make developing for the web easier, faster, and more productive. We’re constantly iterating to add features to make building with Deno even better, and have a lot more coming up in the future.
We’re always open to feedback and feature requests! Feel free to join our growing Discord or create an issue here.
Does your app need async processes or to schedule work in the future?
Deno Queues is a simple way to add scalable messaging and background processing to your app.